Record of Learning of Uring
What is uring?
[Week 1]
SQ: Submission queue based on circular queue
CQ: Completion queue based on circular queue
SQE/CQE: the entry of SQ/CQ
In linux design, SQ only store the serial number of SQEs, CQ store the whole data.
Submission:
- Put SQE in SQEs, record cardinal, update SQ tail.
- Repeat for multiple task.
Completion:
- Kernel complete task, update CQ head.
- User receive task, update CQ tail.
What is a lock free ring buffer?
[Week 2]
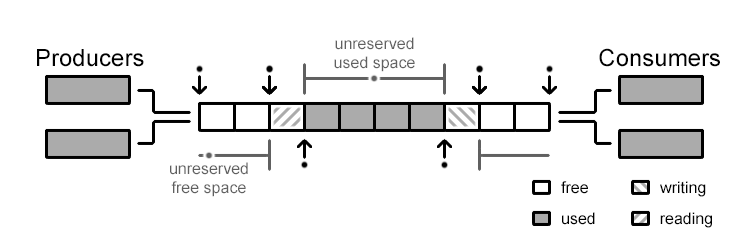
Reserve commit to retain space before really modifying.
[Week 2]
struct Slot<T> {
stamp: AtomicUsize,
value: UnsafeCell<MaybeUninit<T>>,
}
A slot to initiate data and a stamp for atomic operation.
/// one_lap = mark_bit * 2 = 010...0 where one_lap + idx = real_idx
one_lap: usize,
/// size: 001...0 where size - 1 = 00011... as modulo.
mark_bit: usize,
Thus we use one_lap - 1 = 001111 with idx & !(one_lap - 1) to acquire the additional lap of wrapping around.
Suppose a push operation. We first calculate the index and lap which is a wrapping around modulo of index.
let index = tail & (self.mark_bit - 1);
let lap = tail & !(self.one_lap - 1);
let new_tail = if index + 1 < self.buffer.len() {
// index + 1 < len means index is in the same lap.
tail + 1
} else {
lap.wrapping_add(self.one_lap)
};
Then we acquire the data and check whether the stamp is equal to tail index, if so, it means
the local variable tail when the preparation of push and current variable stamp is equal, we
try to exchange the tail to new tail and update the slot of tail.
if tail == stamp {
// Try moving the tail.
match self.tail.compare_exchange_weak(
tail,
new_tail,
Ordering::SeqCst,
Ordering::Relaxed,
) {
Ok(_) => {
// Write the value into the slot and update the stamp.
slot.value.with_mut(|slot| unsafe {
slot.write(MaybeUninit::new(value));
});
slot.stamp.store(tail + 1, Ordering::Release);
return Ok(());
}
Err(t) => {
tail = t;
}
}
...
}
Else, we are in full state that the stamp is ahead of tail, in order to
reflect the critical condition in error handling on Slot<T>,
we should take full_fence() then call back the handling.
else if stamp.wrapping_add(self.one_lap) == tail + 1 {
crate::full_fence();
value = fail(value, tail, new_tail, slot)?;
#[cfg(loom)]
busy_wait();
tail = self.tail.load(Ordering::Relaxed);
} else {
busy_wait();
tail = self.tail.load(Ordering::Relaxed);
}
Where we need the latest slot here.
Design IPC
[Week 1]
IPC (Refactored by AI to reduce redundant design.)
Combine the convenience of uring to establish asynchronous communication.
User:
- call asynchronous kernel function, e.g.
async_read(...). - function will create a
Futurespecific for uring calledUringFuture. spawn()will push the future wrapped asTaskintoExecutor.- When
Executorfirst poll the task, it add it to SQ.
Kernel:
- initiate SQ,CQ,
Executor. - read and implement
SQE. - write
CQEpacked task.
Executor:
- poll task
- submit the SQE of some tasks in batch by
io_uring_submit. - read CQE of its
TaskRefto wake, thus proceed future.
Based on original logic, user calling any kernel asynchronous task will put on the SQE.
Kernel has Executor and Reactor
Tokio-Uring
[Week 1]
Tokio uring initialize io-uring SQ,CQ and epoll based runtime. Using asynchronous task epoll_wait to notify and draining all completion tasks.
When the kernel pushes a completion event onto the completion queue, “epoll_wait” unblocks and returns a readiness event. The Tokio current-thread runtime then polls the io-uring driver task, draining the completion queue and notifying completion futures.
Tokio uring use thread-per-core design in which completion future will not implement Send, thus the task awaiting these operations are also not Send.
Thus user need to take care of load balance, a suggestion as follows:
let listener = Arc::new(TcpListener::bind(...));
spawn_on_each_thread(async {
loop {
// Wait for this worker to have capacity. This
// ensures there are a minimum number of workers
// in the runtime that are flagged as with capacity
// to avoid total starvation.
current_worker::wait_for_capacity().await;
let socket = listener.accept().await;
spawn(async move { ... });
}
})
Tokio uring use ownership to take over resource control to avoid cancellation problem.
/// The caller allocates a buffer
let buf = buf::IoBuf::with_capacity(4096);
// Read the first 1024 bytes of the file, when `std::ops::Try` is
// stable, the `?` can be applied directly on the `BufResult` type.
let BufResult(res, buf) = file.read_at(0, buf.slice(0..1024)).await;
the operation futures may not own data referenced by the in-flight operation. The tokio-uring runtime will take ownership and store resources referenced by operations while they are in-flight.
Thus runtime will take over the resource by:
struct IoUringDriver {
// Storage for state referenced by in-flight operations
in_flight_operations: Slab<Operation>,
// The io-uring submission and completion queues.
queues: IoUringQueues,
}
struct Operation {
// Resources referenced by the kernel, this must stay
// available until the operation completes.
state: State,
lifecycle: Lifecycle,
}
enum Lifecycle {
/// The operation has been submitted to uring and is currently in-flight
Submitted,
/// The submitter is waiting for the completion of the operation
Waiting(Waker),
/// The submitter no longer has interest in the operation result.
Ignored,
/// The operation has completed. The completion result is stored.
Completed(Completion),
}
Operationstruct keeps the data referenced by the operation submitted to kernel.- Runtime will allocate the
Operationto store data which submitted operation needs asSubmittedstate. - If runtime receive the completed results, it store the results and transitions to
Completedstate. - If future drops before the operation complete, drop function will remove the request otherwise it set the state to
Ignoredand submit a cancellation request to Kernel.
Evering
[Week 2]
Uring
A lock-free deque by atomic operation.
pub trait UringSpec {
type A;
type B;
type Ext = ();
fn layout(size_a: usize, size_b: usize) -> Result<(Layout, usize, usize), LayoutError> {
let layout_header = Layout::new::<Header<Self::Ext>>();
let layout_a = Layout::array::<Self::A>(size_a)?;
let layout_b = Layout::array::<Self::B>(size_b)?;
let (comb_ha, off_a) = layout_header.extend(layout_a)?;
let (comb_hab, off_b) = comb_ha.extend(layout_b)?;
let comb_hab = comb_hab.pad_to_align();
Ok((comb_hab, off_a, off_b))
}
}
A uring is based on a continguous memory layout: header|buf_A|buf_B, we expose the api for finer manipulation by user. In order for a tight layout, buf_A and buf_B should has array size as power of 2. In order to restrict the input size, we use the Pow2 with const fn new(pow:usize) -> Pow2 as a compile time check.
A RawUring is a ptr copy to the memory layout. For example, UringA or UringB will initiate the buffer as a Queue structure to manipulate it, e.g.
impl<S: UringSpec> UringReceiver for UringA<S> {
type T = S::B;
fn receiver(&mut self) -> Queue<'_, Self::T> {
self.queue_b()
}
}
Reasonably, we can copy many RawUring for specific UringA as multiple producer and UringB as consumer.
Queue is a structure with a known Range and ptr to the buffer. Range contains head and tail by atomic operation to achieve lock-free. Thus implement enqueue, dequeue etc…
Driver
In order to understand driver, we should know why we need it.
pub struct Runtime<P, U: Uring> {
pub executor: Executor,
pub uring: RefCell<U>,
pub driver: Driver<P, U::Ext>,
pub pending_submissions: RefCell<VecDeque<LocalWaker>>,
}
A runtime contains uring, executor/reactor, driver. We know executor/reactor can spawn asynchronous task or Future and wake executor by Waker. A uring can handle the connection between client and server(Or any terminology based on such communication model.) by submitting the task and receiving the completion. In order to construct a connection between Future and uring that wakes certain submitted task in polling, we need a Driver as a intermediation to tackle.
Driver need to submit certain operation to record the uring send data and therefore in future logic, can poll based on the state of submitted operation by the extracted waker to achieve asynchronous communication.
Now we format explicitly:
- A asynchronous function is called which internally calls
submitto register aOponDriver. submitwill send the related data to uring SQ.- Kernel side will do its work to push the results to
CQ Driverhas a repetition loop to retrieve data from CQ and transform if needed.- The asynchronous function has a future logic call
Driverto retrieve data if could or register the waker if initiated. - Then we await the answer!
We abstract below:
Submitter = Bridge<Submit>, Receiver = Bridge<Receive> where Bridge { driver: Driver }.
Each must own a reference to Driver to retrieve or receive data. Driver is a cache can be quickly read/written lock-free(However, there seems no such data structure in no-std environment, so we choose a lock_api with a Driver<L> where L = lock_api::Mutex).
Driver<T> {
cache: Slab<Opsign<T>>,
}
enum OpState<T> {
Waiting(Waker),
Completion(T),
}
Opsign<T> {
state: OpState<T>,
}
A problem is the abnormal workflow when future drops but the data transmission still working. If future drops, whether or not the data is received successfully, we need to discard it.
OpSign<T> {
state: OpState<T>,
cancelled: AtomicBool,
}
We use a AtomicBool to indicate the discard signal when future drop(fut). Thus when we will check the state and drop the data received.
Unlucky, the repo of original doesn’t suitably design the structure and everything messy here.
Shared Memory
[Week 5]
pub struct ShmBox<T: ?Sized>(NonNull<T>);
ShmBox is a Box<T>-like structure with life time handled by shared memory related allocator.
Given a allocator, allocate a continuous memory range:
/// [`ShmHeader`] contains necessary metadata of a shared memory region.
///
/// Memory layout of the entire shared memory is illustrated as below,
///
/// ```svgbob
/// .-----------------------------------------------------------------------------.
/// | | | | |
/// | [1] uring offsets | [2] allocator | [3] uring buffers | [4] free memory ... |
/// | ^ | | | ^ |
/// '-|-------------------------------------------------------------------------|-'
/// '-- start of the shared memory (page aligned) |
/// end of the shared memory --'
/// ```
The design is raw, given a finite range, the allocator must ensure that it allocates everything inside the range for file mapping. Then we should handle everything with NonNull<T> explicitly. We also need a static life time file descriptor to maintain a consistency.
Thus a independent allocator with concrete memory layout could be used as a isolated shared memory constructor as ShmBox<T,A>. A box can be coupled with inter-process atomic Mutex for reading/writing, or better, a signal design if possible with uring.
A general design should use a A:Allocator, however, rust tends to use global allocator and the related api is experimental. Rather, if we want to develop a independent part of memory management, we should use NonNull<T> as mentioned before, it’s unbearable considering the maintaining period.
As for the layout, it would cast to the allocator itself with its best on memory continuity, thus, allocator + uring + free memory as a unified instance solely with stable exposed api.
In Shared Memory
Metadata/header of ring in registry for resolving buffer. Thus the registry manage the lifetime of buffer ring. One could allocate or deallocate or resolve ring from it.
impl<H: Envelope, A: MemAllocator> Resource for TokenQueue<H, A> {
type Config = usize;
type Ctx = A;
fn new(cfg: Self::Config, ctx: Self::Ctx) -> (Self, Self::Ctx) {
let cap = cfg;
let alloc = ctx;
let h = Header::new(cap);
let buffer: PBox<_, A> = PBox::new_slice_in(
cap,
|i| Slot {
stamp: AtomicUsize::new(i),
value: UnsafeCell::new(MaybeUninit::uninit()),
},
alloc,
);
let (buf, alloc) = buffer.token_with();
(TokenQueue { h, buf }, alloc)
}
fn drop_in(self, ctx: Self::Ctx) -> Self::Ctx {
let alloc = ctx;
let Self { h: _, buf } = self;
let b = buf.detoken(alloc);
PBox::drop_in(b)
}
}
impl<H: Envelope, A: MemAllocator> Project for TokenQueue<H, A> {
type View = ptr::NonNull<TokenSlots<H, A>>;
fn project(&self, ctx: Self::Ctx) -> (Self::View, Self::Ctx) {
let alloc = ctx;
let (buf, alloc) = self.buf.as_ptr(alloc);
(buf, alloc)
}
}
impl<H: Envelope, A: MemAllocator> QueueOps for QEntryView<'_, H, A> {
type Item = PAToken<H, A>;
#[inline]
fn header(&self) -> &Header {
&self.g.h
}
#[inline]
fn buf(&self) -> &Slots<Self::Item> {
unsafe { self.v.as_ref() }
}
}
struct Sender<T> {
// acquire queue handle and restrict methods.
QueueHandle
}
struct Receiver<T> {
QueueHandle
}
impl Sender<T> {
fn send
}
impl Receiver<T> {
fn recv
}
#[repr(C)]
pub struct Entry<T> {
data: UnsafeCell<MaybeUninit<T>>,
rc: AtomicUsize,
state: AtomicU8,
}
#[repr(transparent)]
pub struct EntryGuard<'a, T> {
e: &'a Entry<T>,
}
pub struct EntryView<'a, T: Project> {
pub g: EntryGuard<'a, T>,
pub v: T::View,
}
impl<T> Entry<T> {
unsafe fn get(&self) -> T {
unsafe { self.data.replace(MaybeUninit::uninit()).assume_init() }
}
unsafe fn get_ref(&self) -> &T {
unsafe { (*self.data.get()).assume_init_ref() }
}
unsafe fn write(&self, data: T) {
unsafe { (*self.data.get()).write(data) };
}
fn init(&self, data: T) -> Result<(), T> {
if self
.state
.compare_exchange_weak(FREE, INITIALIZING, Ordering::SeqCst, Ordering::Acquire)
.is_ok()
{
return Err(data);
}
unsafe {
self.write(data);
}
// state suggests that rc is 0.
self.rc.store(0, Ordering::Relaxed);
self.state.store(ACTIVE, Ordering::Release);
Ok(())
}
fn acquire<'a>(&'a self) -> Option<EntryGuard<'a, T>> {
if self.state.load(Ordering::Acquire) == ACTIVE {
self.rc.fetch_add(1, Ordering::Relaxed);
Some(EntryGuard { e: self })
} else {
None
}
}
fn reset(&self) -> Option<T> {
if self
.state
.compare_exchange_weak(
INACTIVE,
DEINITIALIZING,
Ordering::Acquire,
Ordering::Relaxed,
)
.is_ok()
{
// Me is the sole owner.
let data = unsafe { self.get() };
self.state.store(FREE, Ordering::Relaxed);
Some(data)
} else {
None
}
}
}
impl<T> Clone for EntryGuard<'_, T> {
fn clone(&self) -> Self {
self.e.rc.fetch_add(1, Ordering::Relaxed);
Self { e: self.e }
}
}
impl<T> Drop for EntryGuard<'_, T> {
fn drop(&mut self) {
let prev = self.e.rc.fetch_sub(1, Ordering::Release);
if prev == 1 {
// state must be `ACTIVE` -> `INACTIVE`, ensure ordering release.
self.e.state.store(INACTIVE,Ordering::Release);
}
}
}
impl<T> Deref for EntryGuard<'_, T> {
type Target = T;
fn deref(&self) -> &Self::Target {
unsafe { self.e.get_ref() }
}
}
#[repr(C)]
pub struct Registry<T, const N: usize> {
magic: crate::header::MAGIC,
counts: AtomicUsize,
entries: [Entry<T>; N],
}
pub trait Resource: Sized {
type Config: Clone;
type Ctx;
fn new(cfg: Self::Config, ctx: Self::Ctx) -> (Self, Self::Ctx);
fn drop_in(self, ctx: Self::Ctx) -> Self::Ctx;
}
pub trait Project: Resource {
type View;
fn project(&self, ctx: Self::Ctx) -> (Self::View, Self::Ctx);
}
impl<T: Resource> Entry<T> {
pub fn rinit(&self, cfg: T::Config, ctx: T::Ctx) -> Result<(), T::Config> {
let (res, ctx) = T::new(cfg.clone(), ctx);
self.init(res).map_err(|res| {
res.drop_in(ctx);
cfg
})
}
pub fn rreset(&self, ctx: T::Ctx) -> T::Ctx {
if let Some(data) = self.reset() {
data.drop_in(ctx)
} else {
ctx
}
}
}
impl<T: Project> Entry<T> {
pub fn rview<'a>(&'a self, ctx: T::Ctx) -> (Option<EntryView<'a, T>>, T::Ctx) {
let Some(g) = self.acquire() else {
return (None, ctx);
};
let (v, ctx) = g.project(ctx);
(Some(EntryView { g, v }), ctx)
}
}
Example
// suppose alloc:
let alloc = ...;
let message_queue = MessageQueue::<MyHeader>::new();
// Maybe a better design rather clone everytime for alloc.
let move_to = Move::from(alloc.clone());
let position = PositionMessage { x: 1.0, y: 2.0, z: 3.0, timestamp: 123456 };
let token = move_to.tokenize(position);
message_queue.send(token)?;
let text = TextMessage { content: "Hello".to_string(), priority: 1 };
let token = Serial::tokenize(&text,alloc.clone())?;
message_queue.send(token)?;
if let Some(t) = message_queue.receive() {
if let Ok(position) = Move::detokenize::<Position,_>(t,alloc.clone())? {
println!("Received position: {:?}", position);
}
if let Ok(position) = move_to.detokenize::<Position>(t)? {
println!("Received position: {:?}", position);
} else if let Ok(text) = serial_to.detokenize::<TextMessage>(t)? {
...
}
}
Driver Revisit
mod state {
// FREE -> WAKER -> COMPLETED -> FREE
/// FREE: at initiation
pub const FREE: u8 = 0;
/// WAKER: with `waker`, without `payload`
pub const WAKER:u8 = 1;
/// COMPLETED: with `payload`, possibly with `waker`
pub const COMPLETED: u8 = 3;
}
struct CachePool<T,const N:usize> {
inits: AtomicUsize,
free_head: AtomicUsize,
entries: [Cache<T>; N],
}
type TokenCache<H,M> = Cache<PackToken<H,M>>
struct Cache<T> {
next_free: AtomicUsize,
live: AtomicU32,
state: AtomicU8,
waker: UnsafeCell<MaybeUninit<Waker>>,
payload: UnsafeCell<MaybeUninit<T>>,
}
#[derive(Clone, Copy, Debug, PartialEq, Eq)]
#[repr(C)]
pub struct Id {
idx: usize,
live: u32,
}
struct CacheGuard<'a, T> {
cache: &'a Cache<T>,
id: Id,
}
unsafe impl<T: Send> Send for Cache<T> {}
unsafe impl<T: Sync> Sync for Cache<T> {}
unsafe impl<T: Send> Send for CacheGuard<T> {}
unsafe impl<T: Sync> Sync for CacheGuard<T> {}
// state: init -> waiting(waker) -> completed(T) (after polled, automatically clean itself)
impl<T> Cache<T> {
pub const fn null() -> Self {
}
unsafe fn write_waker(&self, ctx: &Context<'_>) {}
unsafe fn write_payload(&self,payload:T) {}
unsafe fn take_payload(&self) -> T {}
pub fn clean(&self) -> {
{needs_drop?}
}
pub fn complete() -> bool {}
pub fn poll() -> Poll<T> {}
}